HashMap散列函数的设计
HashMap是什么
HashMap是存放键值对的数据结构,使用散列表的物理存储方式提高查找速率。线程不安全。
实现思路是使用Key的HashCode值进行一次hash操作,散列其结果作为数组中的位置,也就是哈希查找过程。

哈希查找需要考虑的问题
+ Hash函数的设计
采用除留余数法,即对哈希表长度取余,能够使对象在散列表中分布较均匀。很多书认为哈希表长度应是较大的质数,而且最好不要是2的整数幂。其解释是二进制数除以2的整数幂时结果得该二进制数的后几位,前面的位丢失等于信息损失。个人不认同该观点,取模将大区域中的元素映射到小区域中,这期间必然会信息丢失,与被除数的设计无关。Java中就把哈希表长度设为$2^n$。
+ 解决冲突的方法
链地址法显然比开放定址法更合适。当冲突很多时,链地址法会退化成链表查询,所以长度大于8的链表会被改进成红黑树,提高了查找效率。
性能的提高
除法消耗性能高,应尽量减少。
如果能用位运算来取代mod操作就能提高一些性能,而我们发现当被除数的二进制数为全1,取模跟位运算&的运算过程是一致的。所以只要确定这个全1的二进制数,就能把取模转换为与运算。
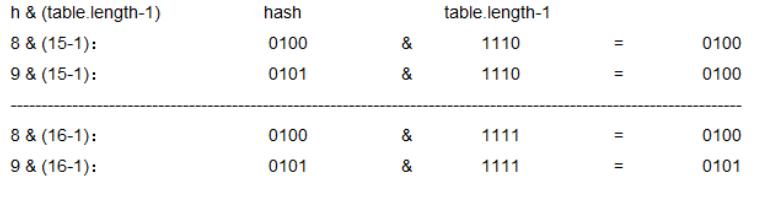
HashMap长度不断变化,取模的操作也应该随之变化,如何设置这个全1的二进制数就成了问题。如果哈希表的长度设置为2的整数幂(HashMap以2倍数拓展),则长度减1就得到全1的二进制数,这个数随HashMap长度扩展而改变,而且天然契合散列表的空间利用。
通过把取模运算转化成与运算,HashMap提高了整体的性能。